
Secure SSH key based Capistrano website deployment from Subversion for multi-developer teams
OK, time for part two in my four part Capistrano series of blog posts. In case you missed it you can find part one here. This is a techie post aimed at experienced website developers so consider yourself forewarned if you read on.
I decided to write this post based on my own experience of trawling Google for help bending Capistrano to my will and finding the lack of a joined up advanced tutorial frustrating. Over the course of this and the next part in my Capistrano series I will write a detailed tutorial going from installation of Capistrano to being in a position to deploy your website using the 'cap deploy' command. There are other tutorials that achieve this but none that:
- a) Really pay attention to the use of SSH keys and the Linux user and permissions setup.
- b) Give a detailed explanation of how to use Capistrano to deploy a LAMP website.
As no one tutorial can fit all use cases I'll outline my hypothetical situation now.
1.1 The hypothetical situation
I am the manager of a development team consisting of about a dozen developers of varying skill levels. We work on multiple websites which we manage as a service for our clients. Our development process consists of three different environments:
- Development
- Staging
- Production
We use Subversion (aka SVN) for version control and a LAMP stack for our websites. Yes we've heard (and believe) that Git has several advantages over SVN but for business reasons we haven't made the jump yet, that battle will be fought another day. All of our servers run using Ubuntu, specifically the 12.04 LTS release. We really like Ubuntu as an operating system as the package management is a cinch.
Our current development process is as follows:
- Developers do their development work on checked out copies of our various projects which run on their local Development machines.
- When a developer is happy with their code changes they commit them back into SVN.
- Periodically SVN tags are taken of a project's codebase. Each SVN tag represents a release candidate for a project.
- The code contained in an SVN tag is released onto the Staging server for testing. The Staging server is as identical as possible to the Production server (e.g. operating system, versions of packages installed etc) so that the likelihood of an uncaught bug appearing in Production is minimised. Each project has its own method of deploying a release candidate to Staging. At best this process is a fully automated bespoke Bash script but some projects rely on developers running though a list of manual commands run (e.g. SVN export followed by rsync followed by several manual file edits).
- If a tag passes testing on Staging then it will be published to the Production server. The same deploy process that was used to publish to Staging will be re-used for publishing to Production.
Releasing has proven to be a painful, time consuming process and recently there have been a few mistakes made by developers causing embarrassing downtime on some of our sites. Developers are complaining that deployment is becoming a Sisyphean task and they're looking to me to come up with some improvements. I've heard great things about Capistrano and want to give that a shot starting with our smallest project "Example.com". The ultimate aim is to get to "one line deploys" for both Staging and Production versions of Example.com. I also want to ensure that deployment is a permissioned activity as only senior developers should be able to push code to Staging or Production, that way they maintain control of the project.
1.2 Understanding how Capistrano works
Before continuing with the technical details of this tutorial it's useful to give a rough overview of how Capistrano works when deploying from Subversion.
At its heart, when you run a Capistrano deploy the following happens:
- Capistrano reads from your Subversion repository to find the exact revision number to deploy. It does this by running an
svn infoquery against your repository from your local machine (i.e. the one Capistrano is installed on). - Capistrano establishes an SSH session with the target server you are deploying to and then from there it remotely invokes the appropriate SVN command to deploy the codebase to a specified folder on that server (e.g.
svn export). - Capistrano then updates a symlink on the target deploy server to point to this folder containing the new release. Your webserver uses the symlink location as the root folder of your website.
Capistrano obviously does a bit more than this, but this is the main thrust of what goes on in a Capistrano deploy.
This means for us our Capistrano situation resembles the following diagram:
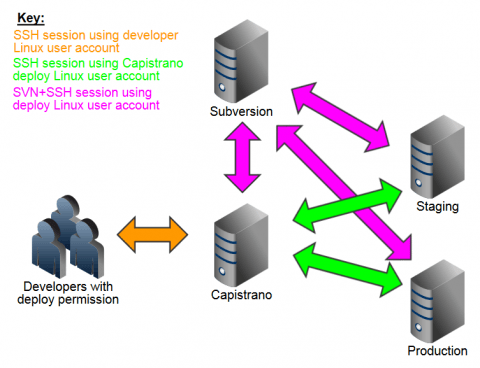
The above is theoretical as it's unlikely you'll create a dedicated VPS just to install Capistrano on. In reality you'll probably install Capistrano on a suitable existing VPS.
Note the colours of the arrows in the diagram above. In order to set up Capistrano we will have to setup these relationships. We'll do that shortly but first let's install Capistrano.
1.3 Installing Capistrano on Ubuntu 12.04 LTS
You can install Capistrano on any Linux server you want really as long as there is connectivity between that server, the SVN server and the Staging and Production servers. Capistrano will need to use the Subversion client to interact with our Subversion repository, so make sure the Ubuntu subversion package is installed on all of the servers in the diagram above.
1.3.1 Installing Ruby on Ubuntu 12.04 LTS
Capistrano is written in Ruby and is itself a RubyGem so we'll need to install Ruby on the server we plan to install Capistrano on. The ruby package in Ubuntu 12.04 is 1.8.7, which is quite old (June 2008). Running:
sudo apt-cache show ruby
Returns:
This is a transitional package which ensures that users of ruby will use ruby1.8
in the future. It can safely be removed.
This isn't a motivator for installing the default Ubuntu 12.04 ruby package. Fortunately there are also the packages ruby1.9.1-full and ruby1.9.3 available in Ubuntu 12.04. 1.9.1 came out in January 2009 and 1.9.3 in November 2011. Running:
sudo apt-cache show ruby1.9.3
Returns:
Ruby uses two parallel versioning schemes: the `Ruby library compatibility version'
(1.9.1 for this package), which is similar to a library SONAME, and the `Ruby version'
(1.9.3 for this package). Ruby packages in Debian are named using the Ruby library
compatibility version, which is sometimes confusing for users who do not follow Ruby
development closely. This package depends on the ruby1.9.1 package, and provides
compatibility symbolic links from 1.9.3 executables and manual pages to their 1.9.1
counterparts.
So 1.9.3 is really a proxy package to 1.9.1, but we might as well go with it. Run the following to install ruby1.9.3
sudo apt-get install ruby1.9.3
After successfully installing Ruby run
ruby --version
This should show that Ruby 1.9.3 is installed.
1.3.2 Installing the Capistrano RubyGem
This is very easy, simply run:
sudo gem install capistrano
Then type the following to confirm that Capistrano installed ok:
cap --version
1.4 Users and permissions for passwordless SSH based deploys
1.4.1 Set up the Capistrano Linux user account
On the Capistrano server we'll create a new user called deploy and a new group called deploy. We're going to store our Capistrano deploy scripts in the home directory of the deploy user (i.e. /home/deploy/). With the correct Linux file system permissions applied then only users who are members of the deploy group (you and your trusted senior developers) will be able to run a Capistrano deploy or edit a deploy script.
NB Other tutorials on the web seem to advise storing Capistrano scripts in the root directory of your application but there is no requirement to do this. I prefer to store my Capistrano scripts in their own version control repository rather than in each application's repository. I also want to restrict the access to them so keeping them all in one permissioned folder works well for me.
To create the deploy user on the Capistrano server type:
sudo adduser deploy
Give the user a temporary password and just leave the rest of the information blank. Now type:
sudo passwd -l deploy
This locks the deploy account so it is available to root only.
We need to create an SSH key for this new deploy user. We can do this as follows:
Start a sudo shell:
sudo -s
Switch to the newly created deploy user:
su deploy
Generate an SSH key for the deploy user:
ssh-keygen -t rsa
Press enter to accept saving the file in the default location (/home/deploy/.ssh/id_rsa) and then just press enter twice when asked to set a password. This ensures this SSH key is passwordless which we want as it will be laborious to have to enter another password in the deploy process. Don't worry all deployers will have to enter their own SSH key password when attempting to deploy so this is still secure.
Now exit the sudo shell by typing:
exit
You will have to add a deploy user and generate an SSH key for every server that Capistrano will be communicating with (i.e. Subversion, Staging and Production in this example). This is important!
1.4.2 Granting a user the ability to deploy
In order to grant a Linux user permission to run a Capistrano deploy we're going to have to do the following:
- On the Capistrano server: Add them to the
deploygroup. This is so they can access the Capistrano deploy scripts stored in thedeployuser's home folder. - On the target servers to deploy to: Add their SSH key to the
deployuser's/home/deploy/.ssh/authorized_keysfile. This is so they have access to the target deploy servers to make filesystem changes etc. - On the Subversion server: Add their SSH key to the
deployuser's/home/deploy/.ssh/authorized_keysfile. This is so they have permission to use the svn+ssh protocol.
You'll have to perform these tasks for every Linux user you want to grant deploy capabilities to. As a convenient example let's do all of the above for your own Linux account now.
1.4.2.1 Adding a user to the deploy group
Adding a user to the deploy group is simple, just run the following command replacing your_username with your actual Linux username:
sudo usermod -a -G deploy your_username
You can confirm this was successful by listing all of the groups that a user is a member of using:
groups your_username
You should see deploy in the returned list.
1.4.2.2 Adding a user's SSH key to the deploy user's authorized_keys file on the target deploy server
Adding an SSH key to the deploy user's authorized_keys file is slightly more fiddly.
Login to your Linux account on the target Capistrano server and list the contents of the .ssh folder within your home folder by typing:
ls -la ~/.ssh
If you've generated an SSH key for your account in the past then should see a couple of files named:
id_rsa
id_rsa.pub
If these files aren't here then run the following to generate them now:
ssh-keygen -t rsa
You'll be prompted for a password. Enter one and remember it as you'll need it each time you deploy.
You'll have to get all your developers to generate SSH keys for their own Linux accounts if they don't have them already.
Now you have to append your key to the deploy user's authorized_keys file on the target deploy server. So, open up another SSH session and log into the target deploy server and then start a sudo shell:
sudo -s
Change to the deploy user's home directory:
cd /home/deploy
Append your Linux account's SSH key from the Capistrano server into the file called authorized_keys using vi (or your favourite Linux text editor). Then set the ownership and permissions for the authorized_keys file as follows:
chown deploy:deploy /home/deploy/.ssh/authorized_keys
chmod 600 /home/deploy/.ssh/authorized_keys
And that's it, to exit the sudo shell run:
exit
1.4.2.3 Configuring Subversion
This is where the complexity of the setup goes up slightly. We'll be using the svn+ssh protocol (see http://svnbook.red-bean.com/en/1.7/svn.serverconfig.svnserve.html#svn.serverconfig.svnserve.sshauth) to access the SVN repos when performing a Capistrano deploy. We use this protocol as it allows us to achieve our goal of passwordless deploys.
As mentioned previously the Subversion client must be installed on the Capistrano server and the target servers we want to deploy to (Staging and Production). If you haven't installed Subversion already you can achieve this by running:
sudo apt-get install subversion
To enable SSH tunnelling edit the file /etc/subversion/config on each server and uncomment the following line in the [tunnels] section:
ssh = $SVN_SSH ssh -q -o ControlMaster=no
And modify the line to read:
ssh = $SVN_SSH ssh -q -o ControlMaster=no –l deploy
The –l parameter specifies the Linux user account when establishing an SSH session to the remote machine. Adding this to the SVN config file means that when someone uses the svn+ssh protocol they are limited to using the deploy user on the Subversion server. We do this as it allows us to tightly control access to the svn+ssh protocol.
I should note that if you run SSH on a non-standard port on your servers then this line should be modified to:
ssh = $SVN_SSH ssh -o ControlMaster=no -l deploy -p XXXX
Where XXXX is the port number you're running SSH on.
Now we're going to create the authorized_keys file for the deploy user on the Subversion server. After you've logged into your Linux account on the SVN server start a sudo shell and edit the authorized_keys file:
sudo –s
cd /home/deploy/.ssh
vi authorized_keys
Add to this file:
- The SSH keys of your deployers (i.e. privileged developers).
- The SSH key of the
deployuser account on the Capistrano server. - The SSH keys of the
deployuser accounts on the target servers to deploy to (Staging and Production).
You should increase security by restricting what SSH sessions on the Subversion server can be used for by placing the SSH keys in the format:
command="svnserve -t --tunnel-user=deploy",no-port-forwarding,no-agent-forwarding,no-X11-forwarding,no-pty TYPE KEY COMMENT
Substituting:
TYPEfor the key type (e.g. ssh-rsa)KEYfor the long SSH keyCOMMENTfor the SSH key comment
This forces all svn+ssh protocol connections to use the SVN username deploy. You can in turn set this SVN account to be limited to read only access within your Subversion repository's configuration.
For more information on this see http://svnbook.red-bean.com/en/1.7/svn.serverconfig.svnserve.html#svn.serverconfig.svnserve.sshauth.
1.5 Creating your first Capistrano script
Now all of the users and permissions are configured we can finally capify our Example.com project. We'll store our Capistrano deploy scripts in a folder called capistrano within the home folder of the deploy user on the Capistrano server. We do this as only users in the deploy group will be able to read or edit the scripts and placing the scripts in one location will make it easy to import them into a dedicated capistrano SVN repository for safe keeping.
On the Capistrano server create the aforementioned folder:
mkdir –p /home/deploy/capistrano
Now for our Example.com project we'll create another directory called example:
cd /home/deploy/capistrano
mkdir example
To create the default set of Capistrano deploy scripts type:
cd /home/deploy/capistrano/example
capify .
You'll see output along the lines of:
[add] writing './Capfile'
[add] making directory './config'
[add] writing './config/deploy.rb'
[done] capified!
If you type:
cap –T
You'll be shown a list of all possible commands you could run for the example project using Capistrano.
1.6 Time out!
OK, that's enough for this week! There's only so much Capistrano one person can take in and I imagine you're at your limit now (I know I am!). In the next part of my Capistrano series I'll go through configuring the newly created 'cap' files so that we can use Capistrano to deploy our 'example' LAMP website.